How GCP Committed Use Discounts work
A Committed Use Discount is a contractual commitment to consume a specified amount of compute resources — vCPUs, memory, or GPU capacity — in a GCP region for either one year or three years. In exchange for the commitment, GCP reduces the effective hourly rate for those resources by up to 57% for memory-optimized machine types and up to 70% for GPU commitments compared to on-demand rates.
CUDs apply at the project level or at the billing account level (when using resource-based commitments). Spend-based commitments apply to all eligible usage across a billing account. Resource-based commitments are tied to specific machine types in specific regions. The distinction matters for multi-project GCP organizations because project-level CUDs can create situations where some projects are over-provisioned against their commitment while others are running on-demand at full price.
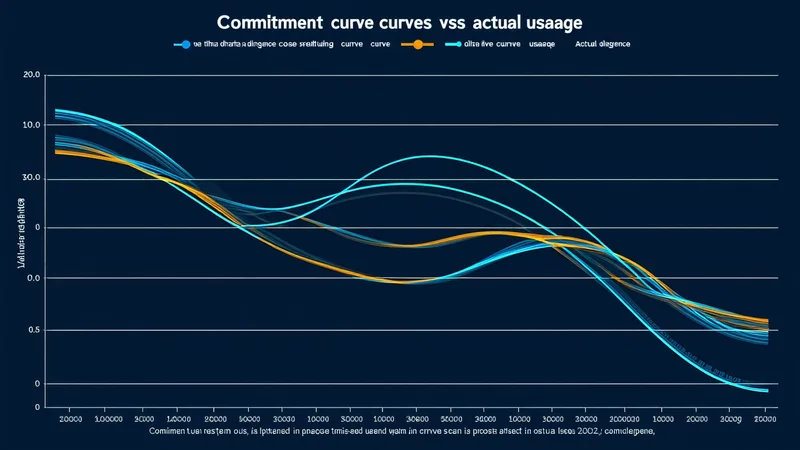
When CUDs produce genuine savings
A CUD produces genuine savings when the resource consumption it covers is consistent, predictable, and sustained. A production Compute Engine cluster that has run at 70%+ vCPU utilization across the committed capacity for the past six months is a strong CUD candidate. The utilization baseline tells you the commitment will be fully consumed. The production workload context tells you the utilization is unlikely to drop significantly during the commitment period.
The most straightforward CUD candidates in most GCP environments are the stable backends that have been running at near-constant load for more than a year — databases, long-running batch processing fleets, and API servers with predictable traffic baselines. These workloads have low variance in their resource consumption, which is the key condition for CUD efficiency.
Three-year CUDs require higher confidence in workload stability than one-year CUDs. The additional discount (roughly 14 percentage points for compute-optimized and memory-optimized types) may be worth the commitment for workloads that have a well-established three-year technology roadmap. They are rarely appropriate for infrastructure that is being actively rearchitected or migrated between service types.
When CUDs create waste
CUDs create waste when the committed capacity is not consumed. If you commit to 100 vCPUs in us-central1 and your actual usage averages 60 vCPUs, you are paying for 40 vCPUs at the committed rate without getting any compute value in return. The effective cost of the hours you actually use rises because you are amortizing the committed-but-unused hours across fewer consumed hours.
The most common waste scenario is CUD over-commitment following a major infrastructure reduction. An engineering team that right-sizes their Compute Engine fleet — eliminating over-provisioned instances — may find that the CUDs purchased before the right-sizing now commit to more capacity than the optimized fleet consumes. The cost savings from right-sizing are partially offset by the cost of unused commitment.
CUDs also create per-team attribution complexity in multi-team GCP organizations. When CUD savings are applied at the billing account level, individual projects appear to be running at on-demand rates in their project-level billing data. The savings only appear at the billing account aggregate level. Teams that believe they are running at on-demand rates when they are actually benefiting from a shared CUD have an inaccurate picture of their true cloud cost.
CUD utilization analysis: what to measure
CUD efficiency is measured by utilization rate — the percentage of committed capacity actually consumed during a billing period. A utilization rate above 85% is generally considered efficient; below 70% indicates the commitment is significantly over-sized relative to actual usage.
Utilization is visible in the GCP Billing Export in BigQuery. The credits column in the billing export includes CUD credit amounts, and usage type breakdowns allow you to see committed vs. on-demand consumption patterns by resource type and region. Building a utilization query from the BigQuery export is straightforward; the harder part is routing that data back to the teams whose workloads are consuming the committed capacity so they understand what portion of their bill reflects committed pricing versus on-demand pricing.
For 1-year CUDs, utilization analysis should be run monthly with a forward-looking projection. A CUD with six months remaining and falling utilization is a signal to either migrate workloads back to covered resource types or to not renew at the current commitment level. For 3-year CUDs, a quarterly review cycle is typically sufficient.
The right team to make CUD decisions
CUD purchase decisions involve both technical judgment (which workloads are stable enough to commit to) and financial judgment (at what commitment level does the NPV of future savings exceed the risk of over-commitment). This is not a decision that either finance or platform engineering should make in isolation.
The most effective CUD governance structure assigns platform engineering the responsibility to produce a quarterly commitment candidate analysis — workloads that meet the utilization and stability criteria for CUD coverage, with projected savings at 1-year and 3-year terms — and gives finance the authority to approve commitment levels based on budget and cash flow considerations. Decisions made with that structure tend to produce commitment levels that are both technically sound and financially appropriate, rather than commitments driven solely by the discount percentage or solely by infrastructure cost projections.